Functional Architecture: Is it the Answer?
C# is an object-oriented language first, but has a number of functional programming capabilities. I like to think that these two approaches compliment each other more than one being superior to the other.
A bit of History
Ten years ago, I was on a project where we believed we were making the “the best software ever”. We were half-joking of course, but the idea was to learn from lessons on previous projects to achieve superior results. This project was small, 3 developers and 1 analyst, working with 2 project stakeholders. This scale allowed us to try some “new” ideas.
“Radical” Approach
We decided from the start that we would focus on two main goals. First, we managed the work in an agile manner. This was the first project I worked on where this was truly the case. It was odd, frustrating and wonderful.
Second, we decided to automate a build process triggered on each check-in of the code. We were using CC.net and Visual SourceSafe. And it worked amazingly well. We automated as many unit tests as we could. And to achieve that, we minimized anything that was not in the business domain portion of the code-base. So very little JavaScript and very little database code. This was prior to the ORM revolution so we were hand-crafting stored procedures. We decided to make these procedures as dumb as possible. All the important parts of the code would be simple C# classes that were straightforward to test.
Success Came Easy
We completed the work, on time and on budget and didn’t break a sweat in the process. We were asked to present our approach and findings to our management team so they could understand what we did that made us successful. Here is one of the slides we presented:
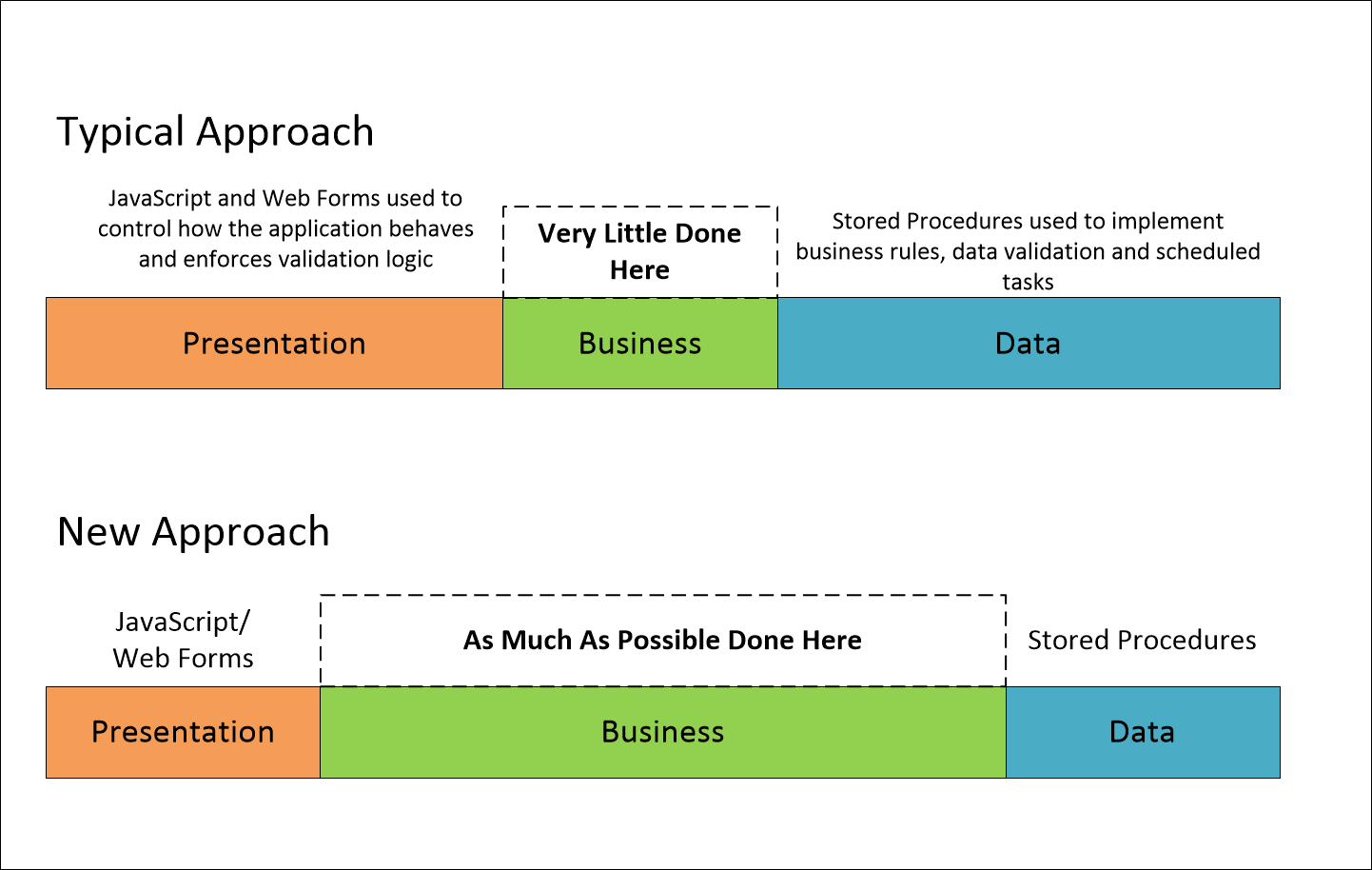
The idea was to look at where decisions were being made in the code. We took three paint buckets to our presentation. One for the UI, one for the Business Logic and one for the Data Access Logic. We filled each bucket with tennis balls, in the proportion used in the “Typical Approach”. We humbly placed fewer balls in the Business Logic bucket. At this time, most applications placed a lot of decision making in the database or in the UI.
Then as we described our new approach we slowly redistributed the tennis balls in the buckets to show how most of the decisions need to occur in the Business Logic portion of the software.
It was a naive idea. But at the time, it felt right and it contributed to a useful piece of software for our client. It led to more work for my company with the client and as far as I know, the software is still in use today.
Maybe a Little Too Easy
That new-found confidence and approach would be put to the test on the next few projects I worked on. None of them felt like successes. They were far more complicated, larger projects with a dozen or more developers (none of whom worked on our little successful project). This new team didn’t practice any of the processes that had brought us success; no automated builds, no automated unit tests, and we relied on the UI and Data Access layers far too much for making decisions in the code base.
It was demoralizing at times and I didn’t think I would feel the same about a project again as I had on that one ten years ago. However, that did not end up being the case. I found a new set of challenges on a few projects and have found inspiration again due to a few key ideas on developing software.
Functional Programming
Last year I took several Pluralsight courses on domain-driven design and functional programming. It was very exciting to be seeing these ideas presented in a way that would seem achievable on real-world projects. With respect to functional programming, I was struck by the simplicity of the seemingly familiar idea.
Functional programming uses pure mathematical functions to develop software. A pure function is one that doesn’t have any hidden inputs or outputs. It has no side-effects. For a given input, the function will always provide the same output.
Here is a sample of a pure function:
public decimal OrderTotal(LineItem[] items)
{
if (items == null)
{
return decimal.Zero;
}
return items.Sum(item => item.Amount * item.Count);
}
This function has no side-effects and won’t throw an exception. It will return the same results for the same inputs every time. The benefit of having more pure functions in your code is the ease they can be understood and tested.
The Approach, Revisited
What made that project ten years ago so successful was the focus on functional programming. I just didn’t realize it at the time. The code we had written was primarily made of simple C# classes and had few side-effects. We didn’t have a lot of ‘decisions’ being made outside of the code domain classes and as such, it made the code very simple to test, maintain and understand.
More formally, this was the way we saw our code:
- Code that makes decisions (the tennis balls)
- Code that acts on those decisions
Code that makes decisions should be expressed as pure functions, wherever possible. This is ths most important code in your application; it’s what makes your application worth value to the project stakeholders. You want to make it as easy to understand and test as possible.
Code that acts on those decisions converts the output from the pure functions into the observable behavior of your application. Namely, data in the database and interactions in the application UI.
At the time this post is being written, functional programming has entered the mainstream and many languages focus heavily on its principals. The software development industry has embraced these ideas and you can find concepts like “pure functions”, “immutable code” and “side-effects” in a lot of articles, books and blogs. It is heartwarming to see so many people better communicating the ideas we had accidentally discovered years ago.
I feel like we only scratched the surface back then. We had no theory behind our ideas, and the tooling support was not as it is today. Revisiting these concepts and approaches today is an exciting experience.
The Functional Approach
A great book for any developer to read is “Unit Testing: Principles, Practices, and Patterns”, by Vladimir Khorikov. More than unit testing, he spends a lot of the book discussing how the design of the software greatly influences the way unit tests are written. The quality of the tests are directly dependent on the quality of your code.
When it comes to functional programming, Khorikov discusses Functional Architecture as an approach to developing software.
His definition is one that speaks to me as something to strive for:
Functional architecture maximizes the amount of code written in a purely functional (immutable) way, while minimizing code that deals with side effects.
Functional Core, Mutable Shell
Khorikov describes the functional architecture as consisting of a functional core and a mutable shell. The functional core is the set of pure functions that make all the decisions. The mutable shell provides the functional core with inputs and acts on the decisions made by the pure functions.
I found this description an excellent approach to construct software. In theory at least. Growing a new piece of software from scratch would allow the architectural freedom to build in this way. However in practice, it is rarely so simple. However, in my opinion, that doesn’t matter. It’s the mindset of the developer that is the most critical thing. Even if some amount of your code cannot be written in this fashion, that’s okay. When you break down a problem into smaller pieces, separate items out into functional core pieces and mutable shell pieces.
The same can be said of many aspects of good software development ideas. Test-Driven Development (TDD) for example. It isn’t that one must practice TDD religiously. It’s your mindset and approach to building and testing in small iterations that the most important practice to follow. Agile software development practices are the same. Agile isn’t a process as much as it’s a state of mind. The most power you can derive from following an agile philosophy is thinking in an agile way. Small pieces of work, estimate as you go, minimize the time it takes to get feedback.
So think functionally and you’ll end up with more pure functions containing your decisions and fewer pieces that cause side-effects.
Testing Styles
Many unit testing books have described the styles of verifying the outcome of a unit test. Khorikov’s is one of the best I have read and it made it possible for me to express my thoughts so much clearer:
- Output-based testing
- State-based testing
- Communication-based testing
Output-based testing is one that pairs nicely with functional programming. The test feeds a given input into a function and the test verifies an expected outcome.
State-based testing verifies the state of the system after the operation has been executed. This style is one you might find more suited for object-oriented techniques. However, it’s a style that can be used with other designs as well.
Communication-based testing uses mocks to verify communication between the system under test and its collaborators. This style of testing should be used as little as possible. It is more difficult to construct such tests and these tests tend to be more brittle and hard to understand.
To favor output-based testing, one has to favor pure functions. So these concepts really are one motivation brought to life in your code; Write simple, pure functions and minimize the side effects and your code will be more testable and understandable.
Working in the Real World
So how does all this work in the real world? In my experience, it depends on a lot of factors. This makes it hard to predict which projects will lend themselves to this approach and which will not.
A mix of Object-Oriented and Functional Code
It is difficulty, if not impossible, to create a purely functional architecture when using an object-oriented language. Take C# for example. It has functional programming support, but as a programming language, its support for object-oriented features is far more natural and extensive.
My approach is to blend the best of both worlds where possible. Suppose for example, there is a class that is responsible for calculating a price discount. It’s API is as follows:
public interface IPriceDiscounter
{
Percent CalculateDiscount(User user, int productId, int itemCount);
}
The discounts are based on a table of values that are too large to store in memory. The implementation of this class must load these values from an external source (a file, or a database for example) and return the result.
So is CalculateDiscount a pure function? No, not by our definition. But while building the implementation, I think of it as being one. That is, given the table of values remains unchanged, the output from this function would be the same for a given set of inputs. That means I can arrange output-based test cases for this class and will make testing it easier to accomplish.
Lean Towards Pure Functions
Where possible, I tend to write pure functions. Even if they are private methods encapsulated within a class. It means there are fewer functions that produce side-effects. Pure functions are much simpler to refactor, and potentially move to different classes as a domain model evolves.
Take for example the following function. It is a private method in a class and it modifies the internal state of an object:
private void CalculateDueDate()
{
if (this.EffectiveDate < DateTime.Today)
{
this.DueDate = DateTime.Today;
}
else if (this.EffectiveDate < this.SentDate)
{
this.DueDate = this.SentDate;
}
else
{
this.DueDate = this.EffectiveDate;
}
}
The details of the logic is not important. The key to this routine is that it manipulates hidden inputs (the class properties) rather than accepting inputs and returning a result.
Here is a functional version of the same logic:
private DateTime CalculateDueDate(DateTime effectiveDate, DateTime sentDate, DateTime today)
{
if (effectiveDate < today)
{
return today;
}
else if (effectiveDate < sentDate)
{
return sentDate;
}
return effectiveDate;
}
I prefer this routine because it is easier to reason about. It is a pure function so it reduces the number of places where side-effects are made. Even within the encapsulated routines of a class, reducing the number of places where side-effects are performed is a desired outcome.
Summary
Using a functional architecture is one approach to software development that I have used informally for some time and have achieved better results. Having a better formal understanding of what a true functional architecture consists of has made it much better for me to discuss and implement. Mixing the concepts of functional programming with object-oriented design is a good balance of design and testing when using C#.